CLIP
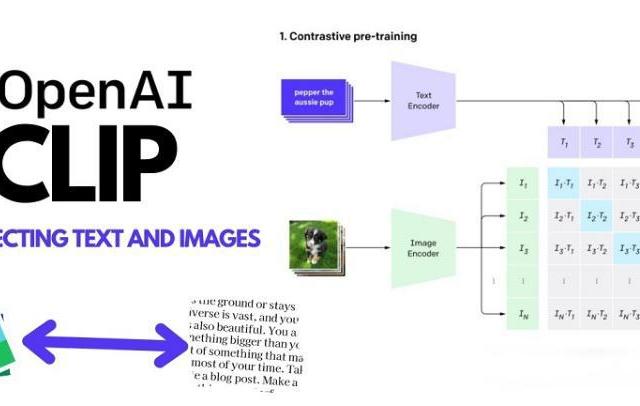
CLIP模型基于AI对图片场景的语义理解,自动生成内容标签。
精选
最新
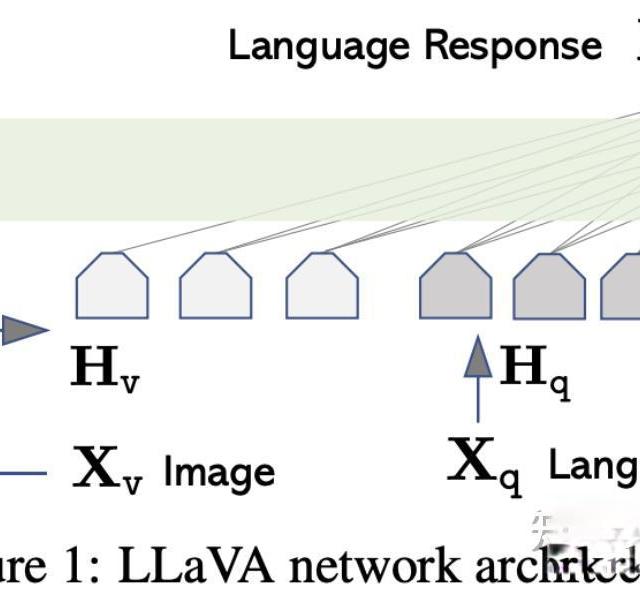
纯文本大模型如何进化为多模态大模型?【LLaVA图文拼接术】
源自UP主: AI扫地曾
赞
2026预训练模型GPU租用平台推荐:实测对比与选型指南
值友1736120759
赞
多模态大语言模型语义理解面经
源自小红薯: 再睡十分钟
赞
多模态到通用感知,第九章 罗塞塔石碑:CLIP 与 SigLIP 的对齐艺术
源自知乎: 北方的郎
赞
多模态大模型是否一定要用CLIP作为Vision encoder?
源自知乎: 烛之文
赞
新手入门!10分钟吃透CLIP多模态核心:从公式拆解到手写数字零样本分类(附服务器可跑全代码)
源自知乎: 机器学习ing
赞
LLM2CLIP:大语言模型驱动的跨模态新范式
源自小红薯: 微软亚洲研究院
赞
Vision Transformer:打破垄断的视觉模型新范式
源自抖音: 众创AI
赞
谁能讲解下扩散模型中Unet的注意力机制?
源自知乎: 叫我Alonzo就好了
赞
图文多模态大模型,视觉backbone一般用什么?
源自知乎: 叫我Alonzo就好了
赞
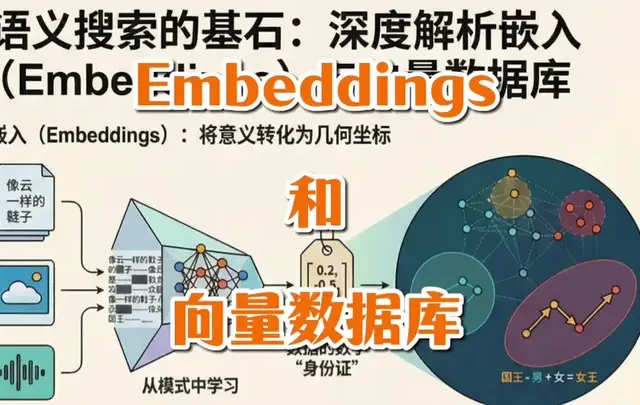
Embeddings和向量数据库 嵌入将数据转化为捕捉语义的多维向量,使计算机能通过数学距离理解概念关联。向量数据库利用HNSW等索引算法实现高效的相似性搜索,避免暴力计算。两者结合支撑了语义检索、RAG及推荐系统,将抽象意义转化为可在大规模数据中检索的几何坐标。 #大模型 #embedding #rag #向量数据库
源自抖音: 一蛙AI
赞
CLIP如何成为多模态的眼睛?
源自UP主: AI扫地曾
赞
AAAI 2026 杰出论文 | 同济&微软等提出 LLM2CLIP:补足 CLIP 难以处理长文本的遗憾
源自公众号: 我爱计算机视觉
赞
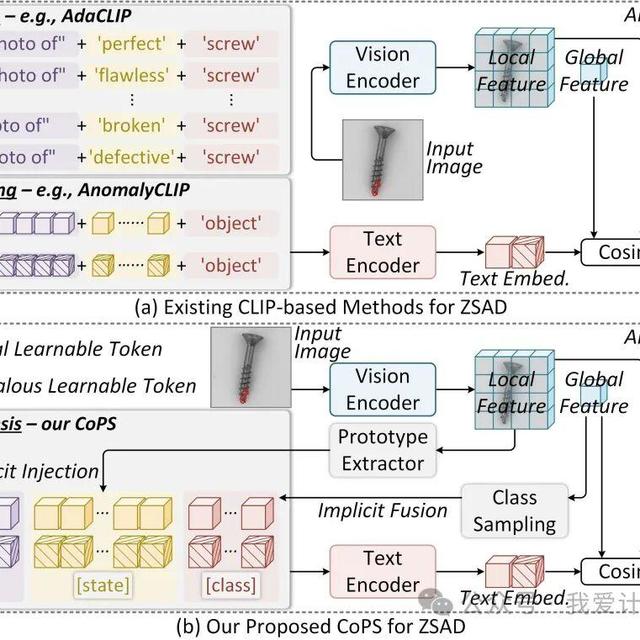
CVPR 2026 Findings | CoPS:让 CLIP 根据图像“现场合成”提示词,迈向更强的零样本异常检测
源自知乎: 我爱计算机视觉
赞
为什么CLIP等基础模型的评估都采用小样本?
源自知乎: 陈昊
赞
985专家讲AI(二十二)多模态大模型原理(五):Transformer和ViT在多模态模型CLIP中的应用
源自UP主: 海波老师-电子科大
赞
超越CLIP,北大开源细粒度视觉识别大模型,每类识别训练仅需4张图像
源自今日头条: 36氪
赞
不脱产CV转多模态大模型,第1个月都做了什么
源自小红薯: 一个算法工程师
赞
DeepSeek 又出神作! AI 的眼睛比脑子更好使
源自小红薯: 小大熊猫看AI
赞
TiFRe:文本引导帧裁剪,高效多模态视频理解
源自小红薯: Python 智能研习社
赞